Here we summarize the result of some benchmark tests performed on RISC-V hardware available as part of the testbed.
RAJAPerf
RAJAPerf tests a suite of loop-based computational kernels relevant for HPC.
DongshanNezhaSTU (Allwinner D1-H)
The DongshanNezhaSTU board contains the Allwinner D1 C906, which supports the V vector extension (version 0.7.1). The chip contains 128-bit wide vector registers and supports element sizes up to 32-bit. Because of this, we compiled RAJAPerf with single percision floating points numbers to enable speedup from vectorization.
We also compare the performance against the StarFive JH7110 (VF2), which contains a quad-core SiFive U74, and a Fujitsu Arm A64FX system, which has SIMD instructions (NEON) as well as scalable vectors (SVE). The A64FX processor is designed for HPC applications and completely different in nature to the RISC-V cores, which are designed for embedded and single-board computers (SBC). However, a comparison against the A64FX is still useful as it can highlight important differences and potential design improvements for an HPC-class RISC-V processor in the future. Because the C906 only contains a single core, all benchmarks are run on a single core to enable direct comparison across CPUs, and only NEON with 128-bit vector width is used on A64FX.
The RISC-V results are compiled using the XuanTie GCC 8.4, with -O3 -march=rv64gcv0p7 -ffast-math for vector and -O3 -march=rv64gc -ffast-math for scalar, and for Arm we used GCC 11.2 with -O3 -ffast-math -mcpu=a64fx -march=armv8.2-a+simd+nosve for vector and -O3 -ffast-math -mcpu=a64fx -march=armv8.2-a+nosimd+nosve for scalar.
In the following plots we show runtimes for the RAJAPerf kernel normalised against the kernel’s scalar runtime. For the A64FX, normalisation is against running in scalar mode on the A64FX, whereas for the Allwinner D1 and StarFive JH7110 it is normalised against running scalar on the D1. The orange and purple bars show the vectorisation performance difference on the A64FX and D1 respectively, and the green bars show a comparison of the scalar performance between the JH7110 (VF2) and the D1.
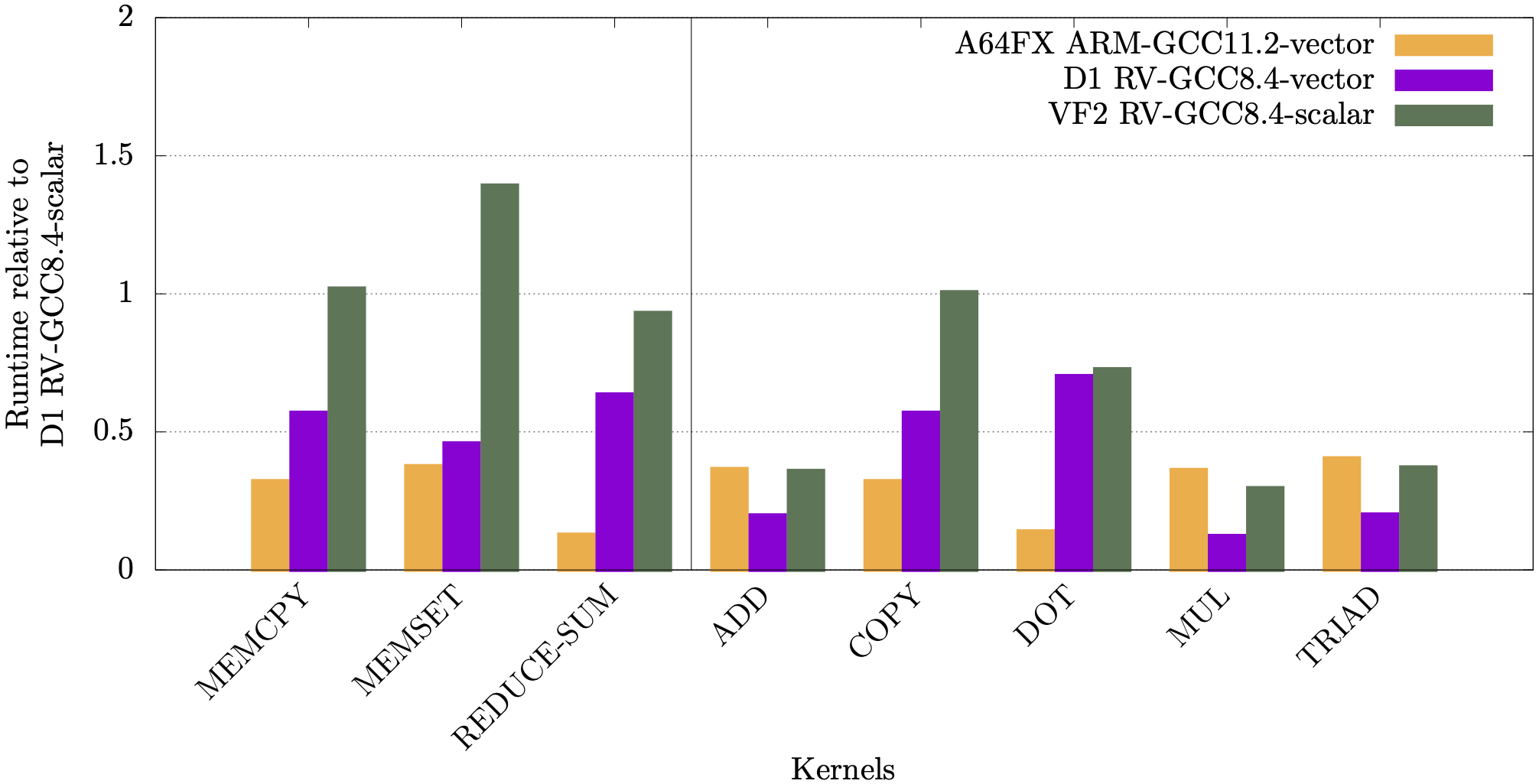
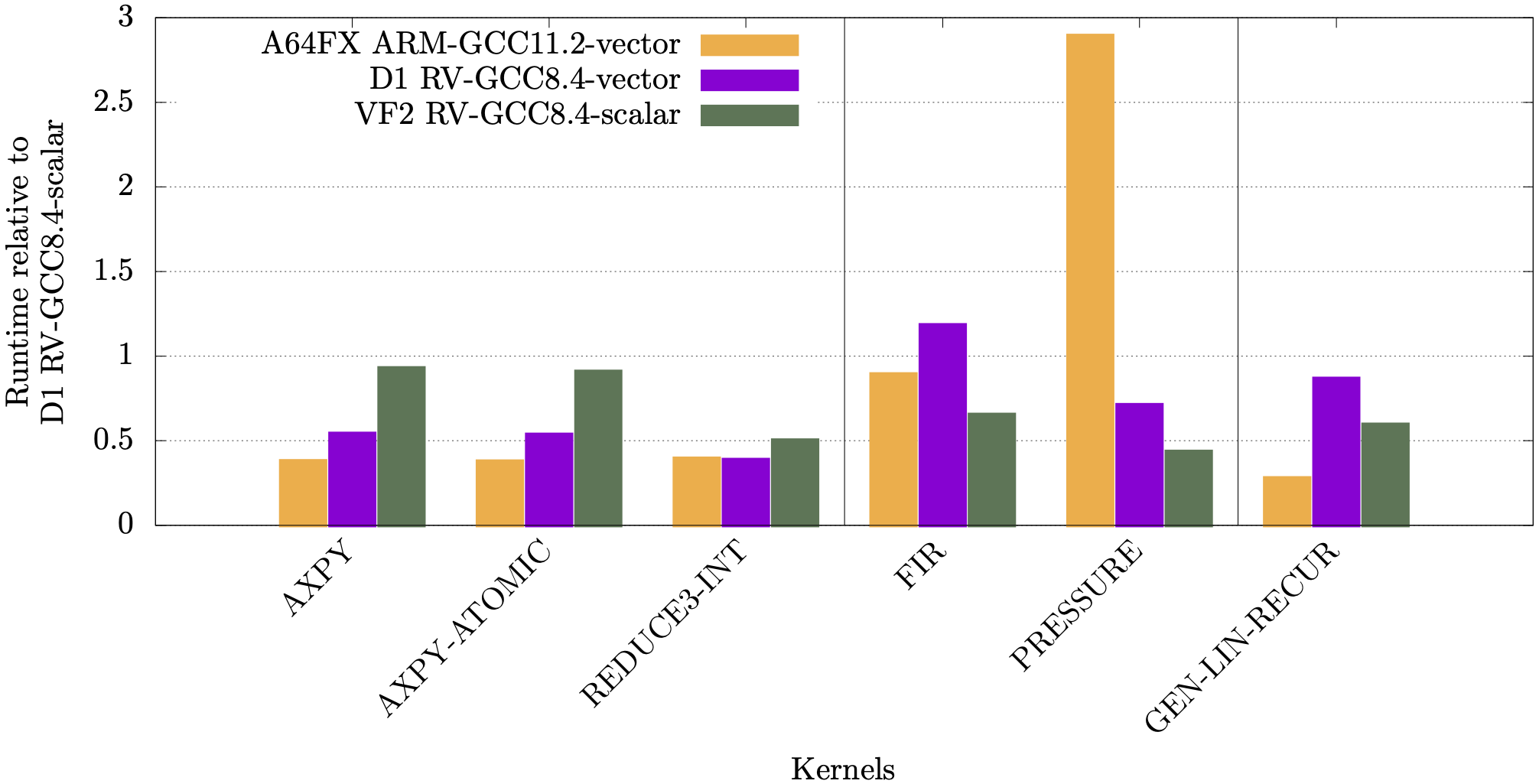
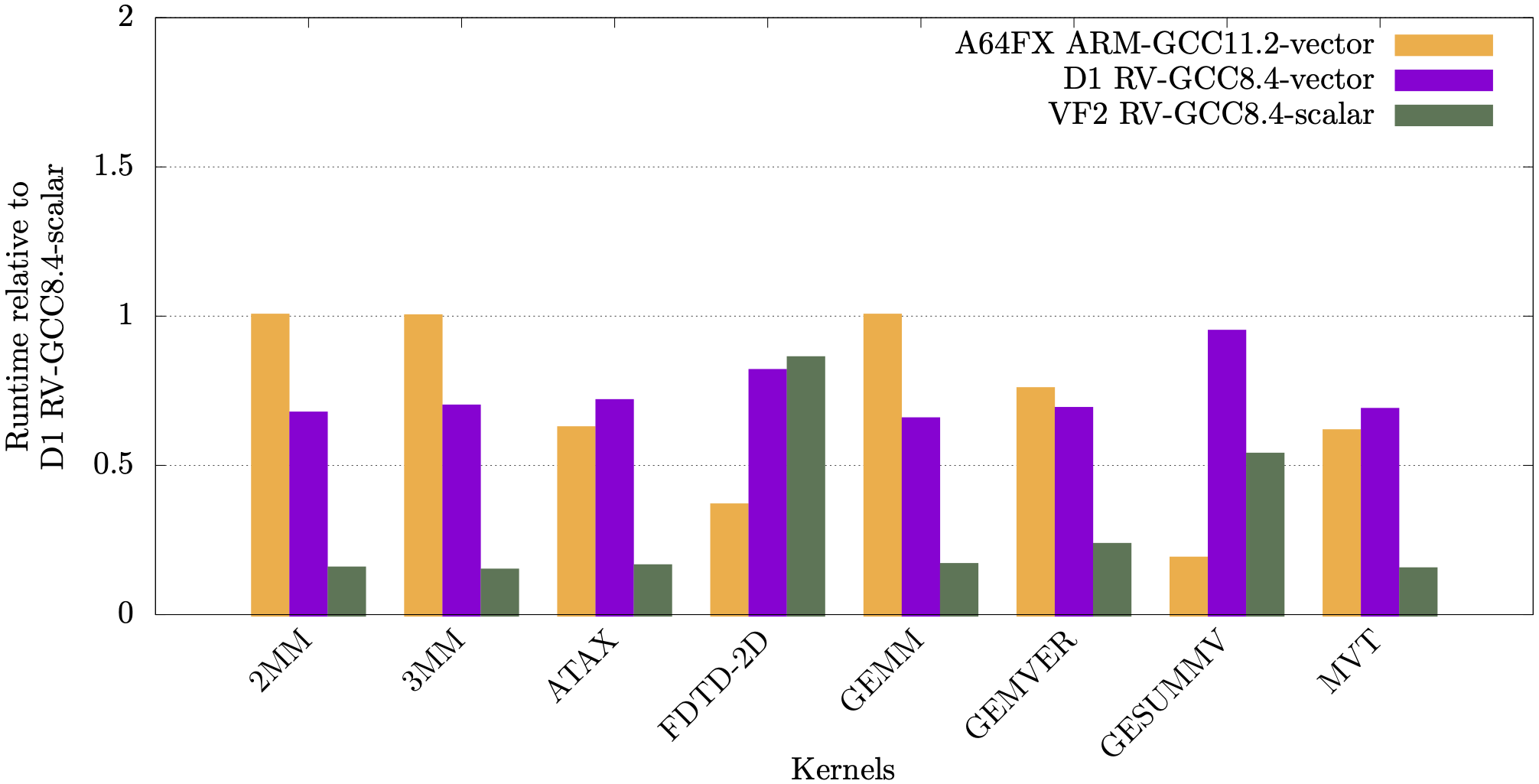
It can be observed from these plots that for most linear algebra kernels, the vectorised code on the RISC-V D1 is faster compared to its scalar counterpart.
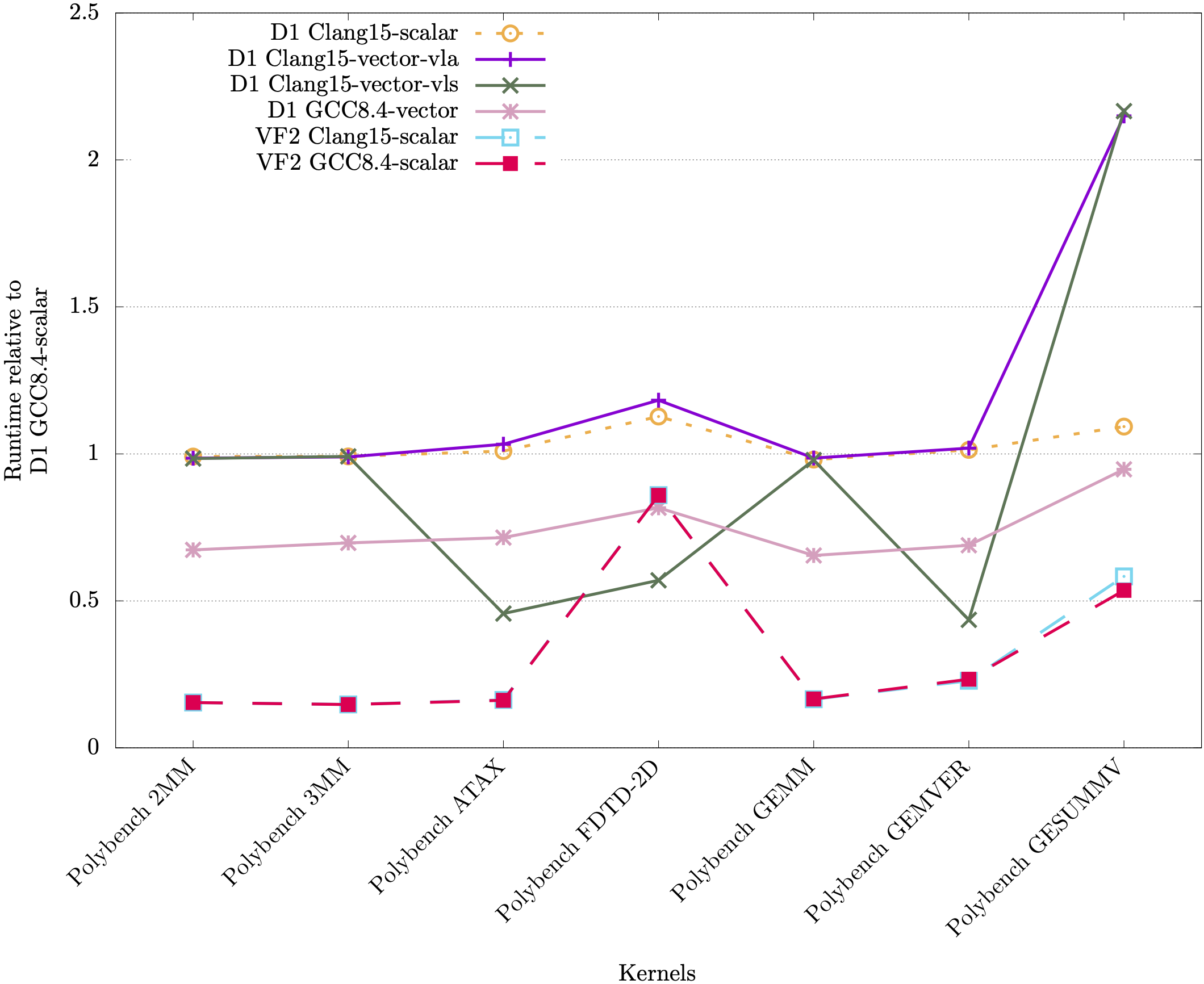
Below we also tested LLVM 15.0, which is able to vectorize more kernels than XuanTie GCC 8.4, but generated RVV 1.0 code. We utilized the RVV-rollback tool https://github.com/RISCVtestbed/rvv-rollback to translate some of the kernels, and the speedup can be seen in the plots below.
Kernels vectorized by GCC:
Kernels not vectorized by GCC:
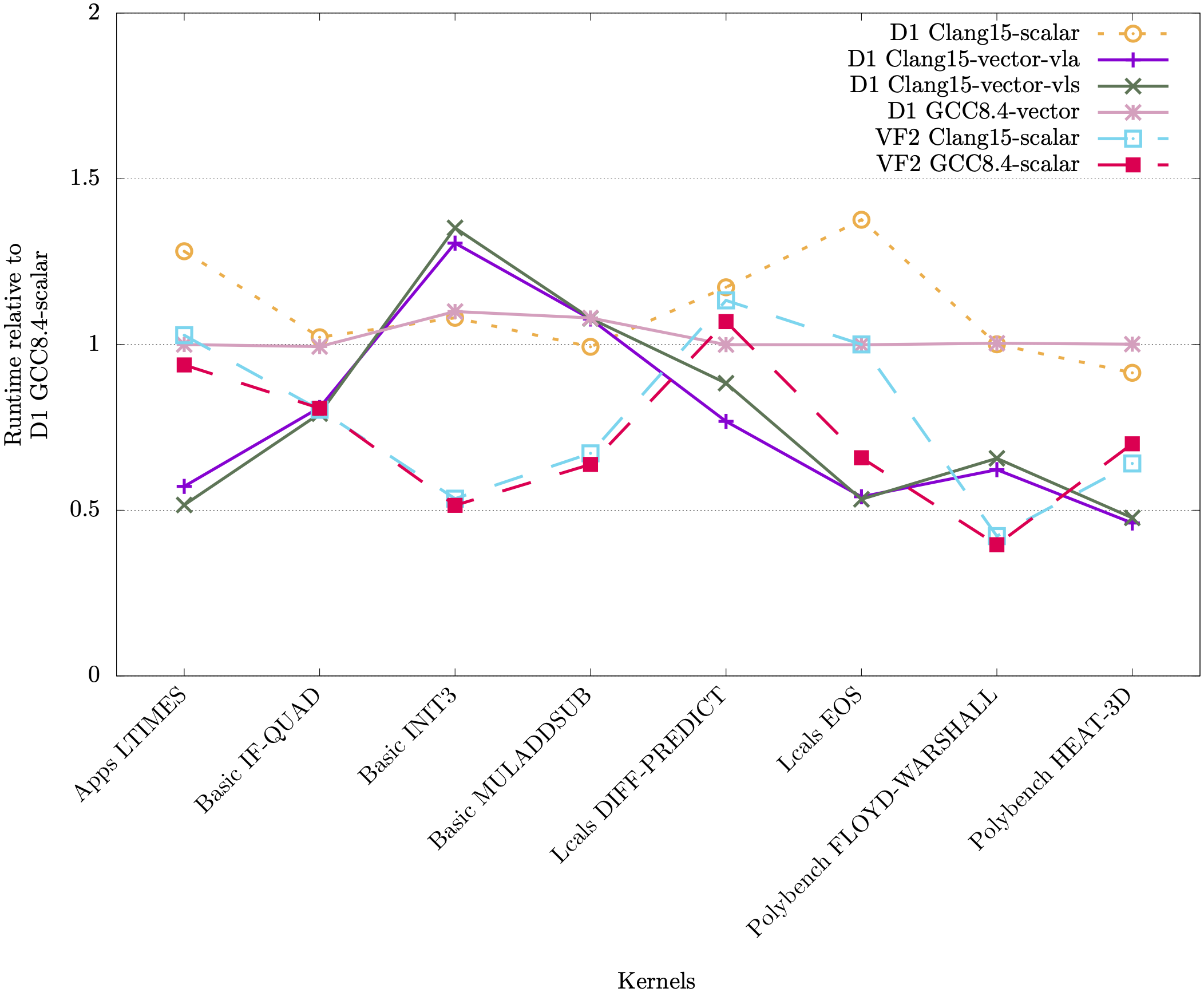
Kernels vectorized by GCC, but no vector instructions were executed at runtime:
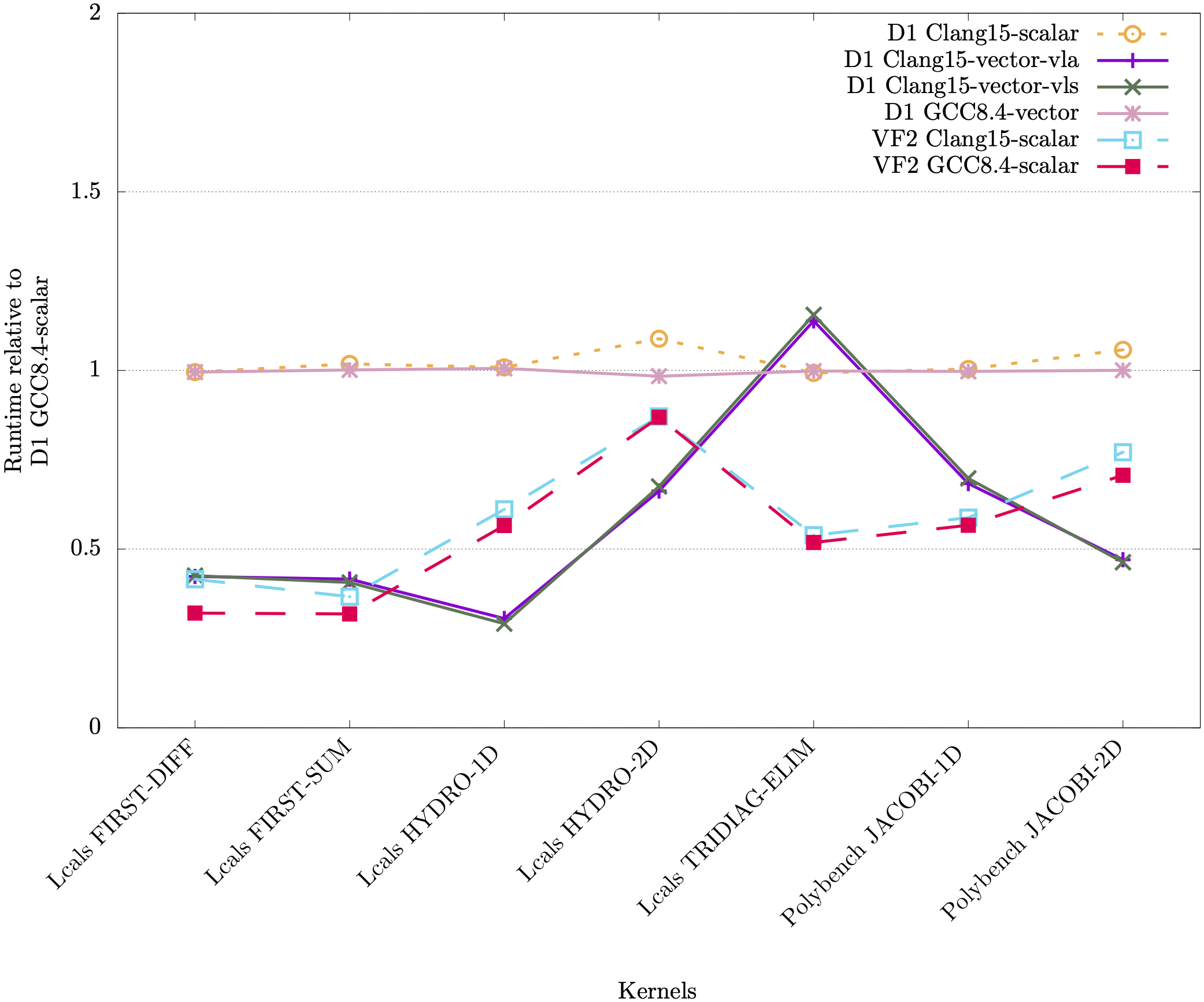
Clang contains settings for vector length specific code (VLS - via -riscv-v-vector-bits-min=128) and vector length agnostic (VLA - via -scalable-vectorization=on), which we showed in the plots above. It can be seen that Clang and GCC have different performance in terms of vectorizing and executing vector instructions for the different kernels.
For more details of the above results, see the following publications:
- Test-driving RISC-V Vector hardware for HPC, J. K. L. Lee, M. Jamieson, N. Brown, R. Jesus
- Backporting RISC-V vector assembly, J. K. L. Lee, M. Jamieson, N. Brown