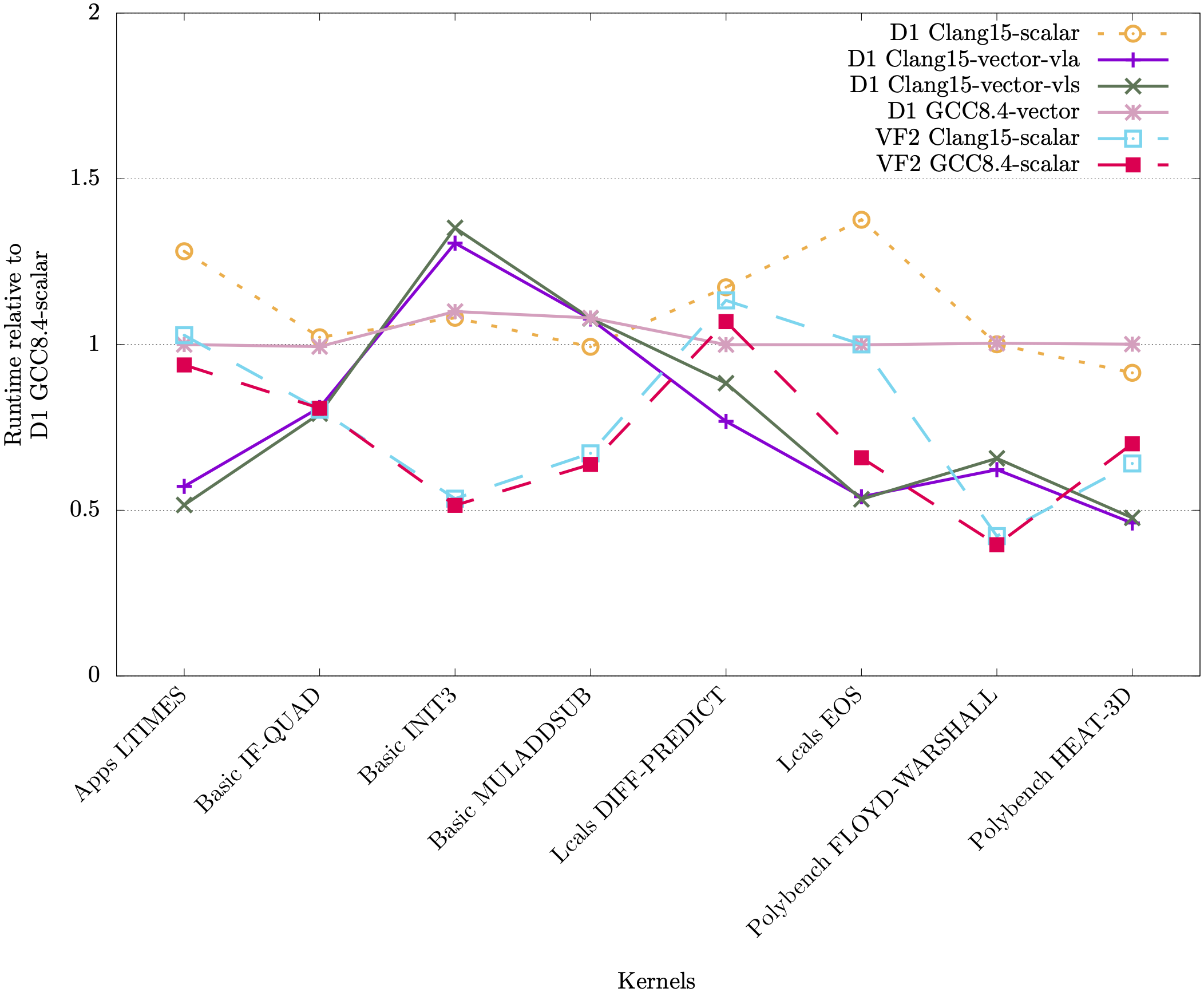
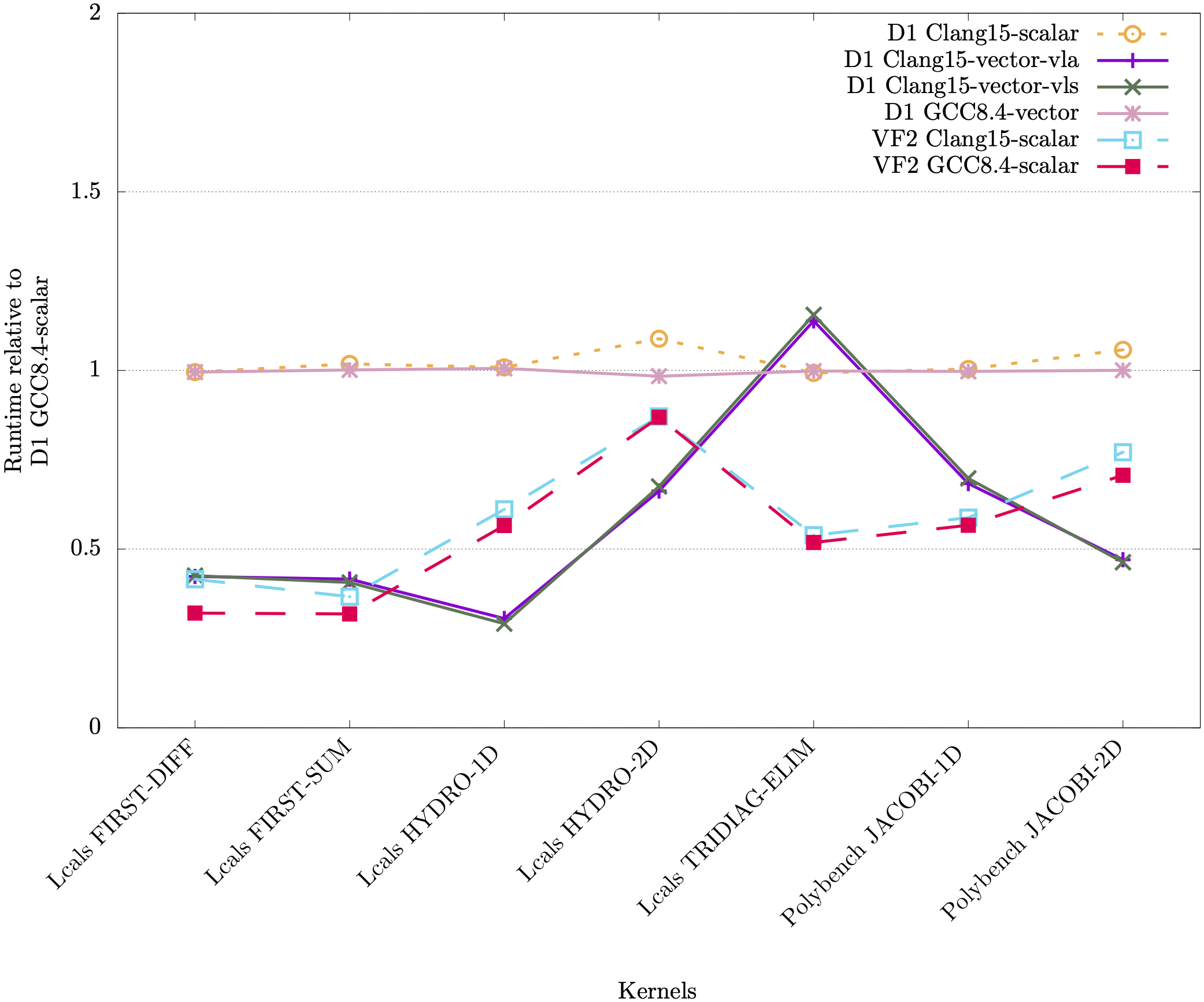
![]()
- Paper Deadline: 6th May 2024 (AoE)
- Author Notification: 20th June 2024
- Camera Ready: 1st July 2024
- Workshop: 26th or 27th August 2024
Workshop details
Co-located with EuroPar 2024, this is workshop will be held on the 26th or 27th of August in Madrid, Spain.
Workshop scope
The goal of this workshop is to continue building the community of RISC-V in HPC, sharing the benefits of this technology with domain scientists, tool developers, and supercomputer operators. RISC-V is an open standard Instruction Set Architecture (ISA) which enables the royalty free development of CPUs and a common software ecosystem to be shared across them. Following this community driven ISA standard, a very diverse set of CPUs have been, and continue to be, developed which are suited to a range of workloads. Whilst RISC-V has become very popular already in some fields, and in 2022 the ten billionth RISC-V core was shipped, to date it has yet to gain traction in HPC.
However, there are numerous potential advantages that RISC-V can provide to HPC and, assuming the significant rate of growth of this technology to date continues, as we progress further into the decade it is highly likely that RISC-V will become more relevant and widespread for HPC workloads. Furthermore, recent advances in RISC-V make it a more realistic proposition for HPC workloads than ever before. An example of this is vectorisation extension which provides important performance advantages for HPC workloads but was only standardised in early 2022, and-so we are only now seeing mature CPUs that fully implement this.
The open and standardised nature of RISC-V means that the large, and growing community, can be involved in shaping the standard and tooling. This is important from two perspectives, firstly it is our opportunity in the HPC community to help shape the future of RISC-V to ensure that it is suitable for the next generation of supercomputers. Secondly, whilst there are a wide variety of RISC-V CPUs currently available, the standard nature of the tooling means that very often the same software ecosystem comprising the compiler, operating system, and libraries will run across these whilst requiring few changes.
This workshop aims to bring together those already looking to popularise RISC-V in the field of HPC with the supercomputing community at-large. By sharing benefits of the architecture, success stories, and techniques we hope to further popularise the technology and increase involvement by the community.
Call for papers - workshop topics
We invite submissions of high-quality, original research results and works-in-progress on RISC-V with a general connection to HPC. Topics of interest for this workshop include (but are not limited to):
- Example use-cases and case-studies that use RISC-V
- Lessons learnt from leveraging RISC-V in HPC
- Industry papers exploring the use of RISC-V
- The porting of codes to RISC-V
- Novel hardware and accelerators built upon RISC-V
- Tools and techniques to aid in the use of RISC-V for HPC
- Developments in HPC libraries to port them to RISC-V
- Enhancements to RISC-V to make the architecture more suited for HPC
- Compiler and runtime support for RISC-V
- The RISC-V ecosystem
- Future gazing how RISC-V might evolve the HPC community
- And anything else related to RISC-V and HPC!
Paper submission
Authors are invited to submit unpublished, original work. Accepted papers will appear in the post-conference workshop proceedings in the Springer Lecture Notes in Computer Science (LNCS) series and submitted versions available online for the workshop. Submissions of original work between 10 and 12 pages (the page count does not include references) are welcomed on work-in-progress, position papers, or mature work. All papers should be submitted via EasyChair here
All papers should be formatted Springer single column LNCS style, with formatting information and templates here
Organisation
Organising committee
- Nick Brown (EPCC at the University of Edinburgh)
- Michael Wong (Codeplay)
- John Davis (Independent)
Program committee
- Oliver Perks (Rivos)
- John Leidel (Tactical Computing Labs)
- Maurice Jamieson (EPCC)
- Ruyman Reyes (Codeplay)
- Luis Plana (BSC)
- Joseph Lee (EPCC)
- Luc Berger-Vergait (Sandia National Laboratories)
- Teresa Cervero (BSC)
- Chris Taylor (Tactical Computing Labs)
- John Davis